2.3 O que Julia pretende alcançar?
NOTE: Nessa seção explicaremos com detalhes o que faz de Julia uma linguagem de programação brilhante. Se essa explicação for muito técnica para você, vá direto para Section 4 para aprender sobre dados tabulares com
DataFrames.jl.
A linguagem de programação Julia (Bezanson et al., 2017) é relativamente nova, foi lançada em 2012, e procura ser fácil e rápida. Ela “roda como C8, mas lê como Python” (Perkel, 2019). Foi idealizada inicialmente para computação científica, capaz de lidar com uma grande quantidade de dados e demanda computacional sendo, ao mesmo tempo, fácil de manipular, criar e prototipar códigos.
Os criadores de Julia explicaram porque desenvolveram a linguagem em uma postagem em seu blog em 2012. Eles afirmam:
Somos ambiciosos: queremos mais. Queremos uma linguagem open source, com uma licença permissiva. Queremos a velocidade do C com o dinamismo do Ruby. Queremos uma linguagem que seja homoicônica, com verdadeiros macros como Lisp, mas com uma notação matemática óbvia e familiar como Matlab. Queremos algo que seja útil para programação em geral como Python, fácil para estatística como R, tão natural para processamento de strings quanto Perl, tão poderoso para álgebra linear quanto Matlab, tão bom para integrar programas juntos quanto shell. Algo que seja simples de aprender, mas que deixe os hackers mais sérios felizes. Queremos que seja interativa e que seja compilada.
A maioria dos usuários se sentem atraídos por Julia em função da sua velocidade superior. Afinal, Julia é membro de um clube prestigiado e exclusivo. O petaflop club é composto por linguagens que excedem a velocidade de um petaflop9 no desempenho máximo. Atualmente, apenas C, C++, Fortran e Julia fazem parte do petaflop club.
Mas velocidade não é tudo que Julia pode oferecer. A facilidade de uso, o suporte a caracteres Unicode e ser uma linguagem que torna o compartilhamento de códigos algo muito simples são algumas das características de Julia. Falaremos de todas essas qualidades nessa seção, mas focaremos no compartilhamento de códigos por enquanto.
O ecossistema de pacotes de Julia é algo único. Permite não só o compartilhamento de códigos, como também permite a criação de tipos definidos pelos usuários. Por exemplo, o pandas do Python usa seu próprio tipo de DateTime para lidar com datas. O mesmo ocorre com o pacote lubridate do tidyverse do R, que também define o seu tipo próprio de datetime para lidar com datas. Julia não precisa disso, ela tem todos os tipos e funcionalidades de datas incluidas na sua biblioteca padrão. Isso significa que outros pacotes não precisam se preocupar com datas. Eles só precisam estender os tipos de DateTime de Julia para novas funcionalidades, ao definirem novas funções, sem a necessidade de definirem novos tipos. O módulo Dates de Julia faz coisas incríveis, mas estamos nos adiantando. Primeiro, vamos falar de outras características de Julia.
2.3.1 Julia Versus outras linguagens de programação
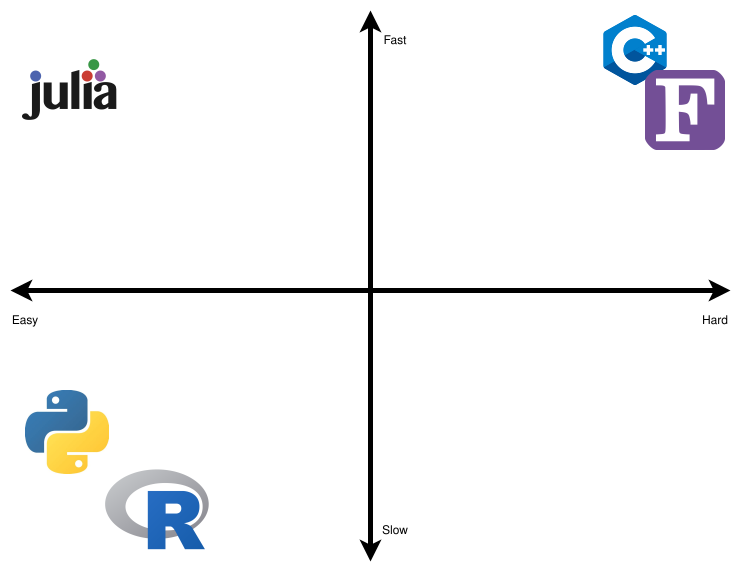
Em Figure 2, uma representação altamente opinativa, dividimos as principais linguagens open source e de computação científica em um diagrama 2x2 com dois eixos: Lento-Rápido e Fácil-Difícil. Deixamos de fora as linguagens de código fechado, porque os benefícios são maiores quando permitimos que outras pessoas usem nossos códigos gratuitamente, assim como quando têm a liberdade para inspecionar elas mesmas o código fonte para sanar dúvidas e resolver problemas.
Consideramos que o C++ e o FORTRAN estão no quadrante Difícil e Rápido. Por serem linguagens estáticas que precisam de compilação, verificação de tipo e outros cuidados e atenção profissional, elas são realmente difíceis de aprender e lentas para prototipar. A vantagem é que elas são linguagens muito rápidas.
R e Python estão no quadrante Fácil e Lento. Elas são linguagens dinâmicas, que não são compiladas e executam em tempo de execução. Por causa disso, elas são fáceis de aprender e rápidas para prototipar. Claro que isso tem desvantagens: elas são linguagens muito lentas.
Julia é a única linguagem no quadrante Fácil e Rápido. Nós não conhecemos nenhuma linguagem séria que almejaria ser Difícil e Lenta, por isso esse quadrante está vazio.
Julia é rápida! Muito rápida! Foi desenvolvida para ser veloz desde o início. E alcança esse objetivo por meio do despacho múltiplo. Basicamente, a ideia é gerar códigos LLVM10 muito eficientes. Códigos LLVM, também conhecidos como instruções LLVM, são de baixo-nível, ou seja, muito próximos das operações reais que seu computador está executando. Portanto, em essência, Julia converte o código que você escreveu — que é fácil de se ler — em código de máquina LLVM, que é muito difícil para humanos lerem, mas muito fácil para um computador. Por exemplo, se você definir uma função que recebe um argumento e passar um inteiro para a função, Julia criará um MethodInstance especializado. Na próxima vez que você passar um inteiro como argumento para a função, Julia buscará o MethodInstance criado anteriormente e redirecionará a execução a ele. Agora, o grande truque é que você também pode fazer isso dentro de uma função que chama uma outra função. Por exemplo, se certo tipo de dado é passado dentro da função f e f chama a função g, e se os tipos de dados passados para g são conhecidos e sempre os mesmos, então a função g gerada pode ser codificada de forma pré-definida pelo Julia na função f! Isso significa que Julia não precisa sequer buscar MethodInstances de f para g, pois o código consegue rodar de forma eficiente. A compensação aqui é que existem casos onde as suposições anteriores sobre a decodificação dos MethodInstances são invalidadas. Então, o MethodInstance precisa ser recriado, o que leva tempo. Além disso, a desvantagem é que também leva tempo para inferir o que pode ser codificado de forma pré-definida e o que não pode. Isso explica por que Julia demora para executar um código pela primeira vez: ela está otimizando seu código em segundo-plano. A segunda e subsequentes execuções serão extremamente rápidas.
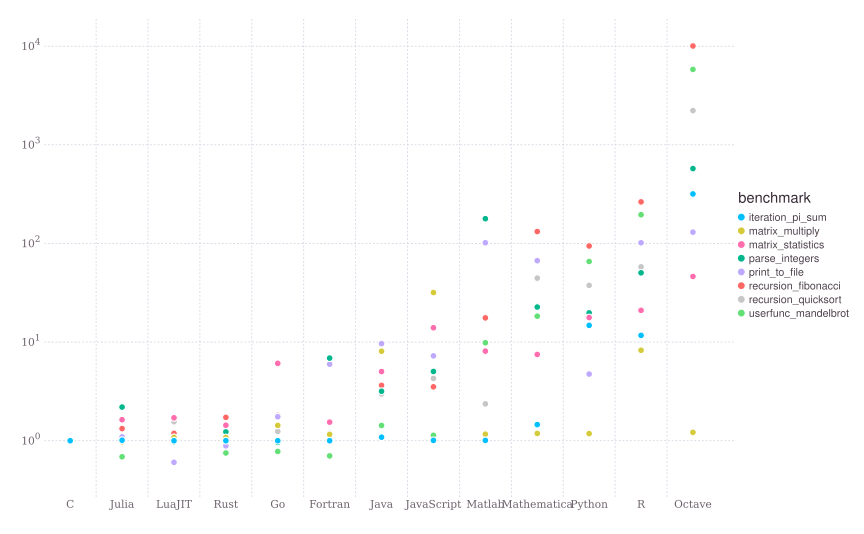
O compilador, por sua vez, faz o que ele faz de melhor: otimiza o código de máquina11. Você encontra benchmarks para Julia e para outras linguagens aqui. Figure 3 foi retirado da seção de Benchmarks do site de Julia12. Como você pode perceber, Julia é de fato rápida.
Nós realmente acreditamos em Julia. Caso contrário, não teríamos escrito este livro. Nós acreditamos que Julia é o futuro da computação científica e da análise de dados científicos. Ela permite que o usuário desenvolva códigos rápidos e poderosos com uma sintaxe simples. Normalmente, pesquisadores desenvolvem códigos usando linguagens fáceis, mas muito lentas. Uma vez que o código rode corretamente e cumpra seus objetivos, aí começa o processo de conversão do código para uma linguagem rápida, porém difícil. Esse é o “problema das duas linguagens” e discutiremos ele melhor a seguir.
2.3.2 O Problema das Duas Linguagens
O “Problema das Duas Linguagens” é bastante comum na computação científica, quando um pesquisador concebe um algoritmo, ou quando desenvolve uma solução para um problema, ou mesmo quando realiza algum tipo de análise. Em seguida, a solução é prototipada em uma linguagem fácil de codificar (como Python ou R). Se o protótipo funciona, o pesquisador codifica em uma linguagem rápida que, em geral, não é fácil de prototipar (como C++ ou FORTRAN). Assim, temos duas linguagens envolvidas no processo de desenvolvimento de uma nova solução. Uma que é fácil de prototipar, mas não é adequada para implementação (principalmente por ser lenta). E outra que não é tão simples de codificar e, consequentemente, não é fácil de prototipar, mas adequada para implementação porque é rápida. Julia evita esse tipo de situação por ser a a mesma linguagem que você prototipa (fácil de usar) e implementa a solução (rápida).
Além disso, Julia permite que você use caracteres Unicode como variáveis ou parâmetros. Isso significa que não é preciso mais usar sigma ou sigma_i: ao invés disso use apenas \(σ\) ou \(σᵢ\) como você faria em notação matemática. Quando você vê o código de um algoritmo ou para uma equação matemática, você vê quase a mesma notação e expressões idiomáticas. Chamamos esse recurso poderoso de “Relação Um para Um entre Código e Matemática”.
Acreditamos que o “Problema das Duas Linguagens” e a “Relação Um para Um entre Código e Matemática” são melhor descritos por um dos criadores de Julia, Alan Edelman, em um TEDx Talk (TEDx Talks, 2020).
2.3.3 Despacho Múltiplo
Despacho múltiplo é um recurso poderoso que nos permite estender funções existentes ou definir comportamento personalizado e complexo para novos tipos. Suponha que você queira definir dois novos structs para denotar dois animais diferentes:
abstract type Animal end
struct Fox <: Animal
weight::Float64
end
struct Chicken <: Animal
weight::Float64
endBasicamente, isso diz “defina uma raposa, que é um animal” e “defina uma galinha, que é um animal.” Em seguida, podemos ter uma raposa chamada Fiona e uma galinha chamada Big Bird.
fiona = Fox(4.2)
big_bird = Chicken(2.9)A seguir, queremos saber quanto elas pesam juntas, para o qual podemos escrever uma função:
combined_weight(A1::Animal, A2::Animal) = A1.weight + A2.weightcombined_weight (generic function with 1 method)E queremos saber se elas vão se dar bem. Uma maneira de implementar isso é usar condicionais:
function naive_trouble(A::Animal, B::Animal)
if A isa Fox && B isa Chicken
return true
elseif A isa Chicken && B isa Fox
return true
elseif A isa Chicken && B isa Chicken
return false
end
endnaive_trouble (generic function with 1 method)Agora, vamos ver se deixar Fiona e Big Bird juntas daria problema:
naive_trouble(fiona, big_bird)trueOK, isso parece correto. Escrevendo a função naive_trouble parece ser o suficiente. No entanto, usar despacho múltiplo para criar uma nova função trouble pode ser benéfico. Vamos criar novas funções:
trouble(F::Fox, C::Chicken) = true
trouble(C::Chicken, F::Fox) = true
trouble(C1::Chicken, C2::Chicken) = falsetrouble (generic function with 3 methods)Depois da definição dos métodos, trouble fornece o mesmo resultado que naive_trouble. Por exemplo:
trouble(fiona, big_bird)trueE deixar Big Bird sozinha com outra galinha chamada Dora também é bom
dora = Chicken(2.2)
trouble(dora, big_bird)falsePortanto, neste caso, a vantagem do despacho múltiplo é que você pode apenas declarar tipos e Julia encontrará o método correto para seus tipos. Ainda mais, para muitos casos quando o despacho múltiplo é usado dentro do código, o compilador Julia irá realmente otimizar as chamadas de função. Por exemplo, poderíamos escrever:
function trouble(A::Fox, B::Chicken, C::Chicken)
return trouble(A, B) || trouble(B, C) || trouble(C, A)
endDependendo do contexto, Julia pode otimizar isso para:
function trouble(A::Fox, B::Chicken, C::Chicken)
return true || false || true
endporque o compilador sabe que A é a raposa, B é a galinha e então isso pode ser substituído pelo conteúdo do método trouble(F::Fox, C::Chicken). O mesmo vale para trouble(C1::Chicken, C2::Chicken). Em seguida, o compilador pode otimizar isso para:
function trouble(A::Fox, B::Chicken, C::Chicken)
return true
endOutro benefício do despacho múltiplo é que quando outra pessoa chega e quer comparar os animais existentes com seu animal, uma zebra por exemplo, é possível. Em seu pacote, eles podem definir um Zebra:
struct Zebra <: Animal
weight::Float64
ende também como as interações com os animais existentes seriam:
trouble(F::Fox, Z::Zebra) = false
trouble(Z::Zebra, F::Fox) = false
trouble(C::Chicken, Z::Zebra) = false
trouble(Z::Zebra, F::Fox) = falsetrouble (generic function with 6 methods)Agora, podemos ver se Marty (nossa zebra) está a salvo com Big Bird:
marty = Zebra(412)
trouble(big_bird, marty)falseAinda melhor, conseguimos calcular o peso combinado de zebras e outros animais sem definir qualquer função extra:
combined_weight(big_bird, marty)414.9Então, em resumo, o código que foi escrito pensando apenas para Raposa e Galinha funciona para tipos que ele nunca tinham visto! Na prática, isso significa que Julia facilita o reuso do código de outros projetos.
Se você está tão animado quanto nós com o despacho múltiplo, aqui estão mais dois exemplos aprofundados. O primeiro é uma rápida e elegante implementação de um vetor one-hot por Storopoli (2021). O segundo é uma entrevista com Christopher Rackauckas no canal do YouTube de Tanmay Bakshi (assista do minuto 35:07 em diante) (tanmay bakshi, 2021). Chris explica que, enquanto utilizava o DifferentialEquations.jl, um pacote que ele desenvolveu e mantém atualmente, um usuário registrou um problema que seu solucionador de Equações Diferenciais Ordinais (EDO) com quaternions baseado em GPU não funcionava. Chris ficou bastante surpreso com este pedido, já que ele não esperava que alguém combinasse cálculos da GPU com quaternions e resolvendo EDOs. Ele ficou ainda mais surpreso quando descobriu que o usuário cometeu um pequeno erro e que tudo funcionou. A maior parte do mérito é devido ao múltiplo despacho e alto compartilhamento de código/tipos definidos pelo usuário.
Para concluir, pensamos que o despacho múltiplo é melhor explicado por um dos criadores de Julia: Stefan Karpinski na JuliaCon 2019.
8. às vezes até mais rápido↩︎
9. um petaflop equivale a mil trilhões, ou um quatrilhão de operações com pontos flutuantes por segundo.↩︎
10. LLVM significa “Máquina Virtual de Baixo-Nível,” ou, em inglês, Low Level Virtual Machine. Você pode encontrar mais sobre a LLVM no site: (http://llvm.org).↩︎
11. se quer saber mais sobre como Julia foi projetada, acesse Bezanson et al. (2017).↩︎
12. observe que os resultados de Julia descritos acima não incluem o tempo de compilação.↩︎